Building A Speech Recognition App Using Javascript - CodeSource.io
In this article, we will build a speech recognition application in javascript without any external api or libraries. We will make use of the
codesource.io
위 포스팅을 참고해서 작성되었습니다.
이번 포스트에서는 외부 API나 라이브러리를 이용하지 않고 순수한 자바스크립트로만 음성 인식 어플리케이션을 만들어 볼 것입니다. 주로 사용하는 것은 브라우저가 가지고 있는 speechRecognition api 입니다.
SpeechRecognition
The SpeechRecognition interface of the Web Speech API is the controller interface for the recognition service; this also handles the SpeechRecognitionEvent sent from the recognition service.
developer.mozilla.org
애플리케이션은 index.html, style.css, app.js 만으로 구성된 굉장히 간단한 세 파일로만 이루어져 있습니다. 핵심은 app.js이므로 index.html은 복붙하고 style.css는 자신의 미적 감각(?)대로 작성합시다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Speech Application</title>
<link rel="stylesheet" href="style.css" />
</head>
<body>
<div class="words"></div>
<script src="app.js"></script>
</body>
</html>
Window 객체에 있는 SpeechRecognition 생성자를 이용해 인스턴스를 하나 만든 후 interimResults 속성을 true값을 주도록 합시다. interimResults은 false값을 주게 된다면 사용자의 첫 단어만을 결과값으로 돌려줄 것입니다. (음절이 아닌 단어가 최소 단위값으로 가지는 것 같습니다.) 반면 true는 단어를 종합하여 문장을 결과값으로 돌려줍니다.
const recognition = new SpeechRecognition();
recognition.interimResults = true;
이해가 잘 안간다면 결과값을 확인해봅시다.
false의 경우 Hello My Name is....라고 말한다면 Hello라는 한 단어만 인식합니다. (한국어도 마찬가지 입니다)

true인 경우 연속된 단어를 종합하여 문장으로 인식하고 있습니다.
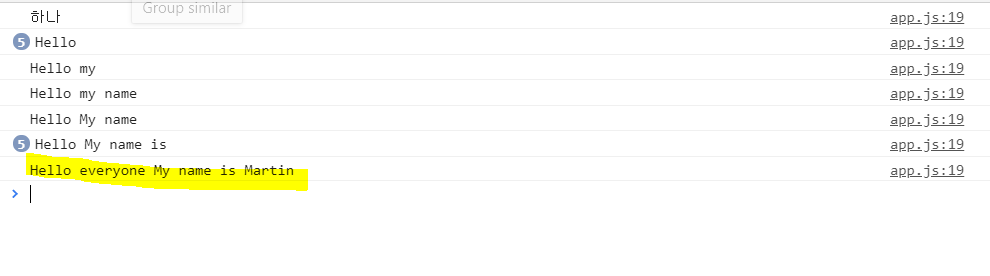
그 외의 특성들은 문서를 읽어보면 이해할 수 있습니다. 여기서 가장 인상 깊은 메서드는 recognition.maxAlternatives입니다. 숫자가 작을수록 발음대로 적고, 크면 문장의 적합도에 따라 알맞은 단어로 대체합니다.
예들들어 "나 오늘 댕장꾹먹었어"을 발음했을 때 maxAlternatives값이 1(default)일 때는 (댕장꾹이란 단어가 실존한다면) 가급적 댕장꾹을 그대로 적지만 높은 값을 주면 문장으로 보건대 "된장국"이 더 적합한 단어이기 때문에 그 단어로 교체합니다.
즉, maxAlternatives에 더 높은 값을 줄수록 발음과 매치되는 대안(Alternatives)이 많아져서 가급적 그 문장에 적합해보이는 단어로 교정해줍니다.
"경찰청 철창살은 외철창살이냐 쌍철창살이냐" 같은 텅트위스트를 발음한다면 maxAlternatives값이 높을수록 음성 인식 api가 알아서 잘 고쳐주겠죠?
window.SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
// 인스턴스 생성
const recognition = new SpeechRecognition();
// true면 음절을 연속적으로 인식하나 false면 한 음절만 기록함
recognition.interimResults = true;
// 값이 없으면 HTML의 <html lang="en">을 참고합니다. ko-KR, en-US
recognition.lang = "ko-KR";
// true means continuous, and false means not continuous (single result each time.)
// true면 음성 인식이 안 끝나고 계속 됩니다.
recognition.continuous = true;
// 숫자가 작을수록 발음대로 적고, 크면 문장의 적합도에 따라 알맞은 단어로 대체합니다.
// maxAlternatives가 크면 이상한 단어도 문장에 적합하게 알아서 수정합니다.
recognition.maxAlternatives = 10000;
let p = document.createElement("p");
p.classList.add("para");
let words = document.querySelector(".words");
words.appendChild(p);
let speechToText = "";
recognition.addEventListener("result", (e) => {
let interimTranscript = "";
for (let i = e.resultIndex, len = e.results.length; i < len; i++) {
let transcript = e.results[i][0].transcript;
console.log(transcript);
if (e.results[i].isFinal) {
speechToText += transcript;
} else {
interimTranscript += transcript;
}
}
document.querySelector(".para").innerHTML = speechToText + interimTranscript;
});
// 음성인식이 끝나면 자동으로 재시작합니다.
// recognition.addEventListener("end", recognition.start);
// 음성 인식 시작
recognition.start();
'웹 전반, 브라우저 > Web API' 카테고리의 다른 글
| Window, Element의 Scroll, 높낮이와 관련된 속성과 메서드들 (0) | 2020.09.04 |
|---|---|
| keycode, code (0) | 2020.07.13 |
| [Web-API] MediaDevices, MediaRecorder를 이용한 영상, 음성 녹화(하드웨어 사용) (0) | 2020.06.21 |
| Fullscreen API (0) | 2020.06.21 |
| [Web-API] getCurrentPosition 메서드 이용하여 유저 위치 파악하기 (0) | 2020.04.05 |
