Redis
Try it Ready for a test drive? Check this interactive tutorial that will walk you through the most important features of Redis. Download it Redis 6.0.9 is the latest stable version. Interested in release candidates or unstable versions? Check the downloads
redis.io
In-Memory Database : 속도 우선. 데이터 내구성은 낮음.
말 그대로 주 메모리에 모든 데이터를 보유하고 있는 데이터베이스. 디스크 검색(HDD, SSD)보다 자료 접근이 훨씬 빠른 것이 장점이고, 인 메모리 데이터베이스를 쓰는 이유이다. NVMe SSD보다도 RAM이 10배 가량 빠르니 당연한 사실.

그러나 메모리라는 특성 상, 서버가 꺼지면 정보도 날아간다. 이와 같은 속성 때문에 '데이터 내구성이 낮다'라고 말해진다. 그래서 보통은 로그인 세션(인증 토큰 저장), 캐시 서버, Pub/Sub 서버, ranking board, 유저 api limit 등에 사용되고 있다.
혹은, Redis에 있는 정보를 별도로 디스크에 저장하는 과정을 거치기도 한다.
단, RAM의 용량은 디스크보다 현저히 낮기 때문에(32GB 램을 장착하더라도 1TB HDD와 용량과 비교하자면...) 많은 양의 데이터는 넣을 수 없고, 비교적 적은 양의 데이터만을 핸들링할 수 있다.
인 메모리 캐시로 Memcached 등이 존재하는데 여기서는 가장 대중적인 Redis를 다뤄보고자 한다.
* Amazon ElastiCache(이건 AWS가 제공하는 서비스가 더 정확한 표현. ElastiCache에서 Redis나 Memcached를 쓴다.) Redis labs라는 redis 서버 호스팅 업체도 존재한다.
Redis
인 메모리 캐시 중에서도 Redis의 특징을 살펴보자면
* key-value 모델의 NoSQL이다.
* Redis는 캐시 서버가 아니라 저장소이다. 하지만 캐시 서버로 활용할 수 있다.
* disk 보다 10배 정도 빠르다.
* data expire가 가능하다. 즉, 지정된 시간 이후 만료가 가능하다.
* 512MB까지만 저장이 가능하다.
* 싱글 스레드다 => 시간 복잡도를 고려해야 한다. O(n) 명령어를 조심해야 한다. keys는 절대 사용 X. conf에서 꺼주자
* atomic critical section : race condition 문제에서 자유로운 편
race condition?
여러 개의 Thread가 경합하여 context switching에 따라 원하지 않는 결과가 발생할 수 있다.
Redis는 atomic critical section에 대한 동기화를 제공하므로 이 문제에서 자유로운 편
Redis 설치 및 Hello World
window면 아래 포스트를 보고 설치를 진행합시다.
https://goni9071.tistory.com/473
https://github.com/microsoftarchive/redis
저는 리눅스 환경에서 진행하도록하겠습니다.
// redis-tools와 redis-server 설치
sudo apt install redis-tools
sudo apt install redis-server
service redis-server start // 시작
redis-cli // redis-server cli 사용
service redis-server stop // 중지
redis-cli에 접근 한 후 key-value로 데이터를 CRUD 해보겠습니다.
set [key] [value] // 값
get [key] // 값 읽기
del [key] // 삭제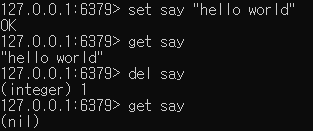
keys * // 존재하는 모든 key들 호출

set [key] [value] ex n // n 초후 삭제됨
ttl [key] // 해당 데이터의 time to live

Redis의 자료 구조
string, hash, list, set, ordered set, steam, binary file, hyperloglog 등 존재.
사실 사용하는 것만 사용하게 된다. hypterloglogs는 사용 해 본 경험이 없다.
* 하나의 컬렉션에 너무 많은 아이템을 담지 않는 것이 좋음. 예를 들어 리스트에 요소가 100000개 들어 있다던가, hash에 key가 10000개 있다던가. 한 컬렉션에는 아이템 n천개 수준이 좋음. 가능하면 1만개를 넘어가지 않게 하자.
* expire는 item별로 걸리지 않고 전체 collection에 걸림. 예를 들어 1000개의 아이템을 가진 자료 구조에 expire가 걸려 있다면 그 시간 후에 1000개가 전부 삭제됨.
1. Hash data : hset/hget
HSET – Redis
Sets field in the hash stored at key to value. If key does not exist, a new key holding a hash is created. If field already exists in the hash, it is overwritten. As of Redis 4.0.0, HSET is variadic and allows for multiple field/value pairs. *Return value
redis.io
h 관련 명령어가 일목요연하게 정리되어 있으니 살펴보자. 역시 공식문서가 제일 좋다.
Sets field in the hash stored at key to value. If key does not exist, a new key holding a hash is created. If field already exists in the hash, it is overwritten.
그러니까, 정확한 용어는 아니지만 hash data는 json 같은 형식을 말하는 것이다.
키-밸류 값으로 설정된다면, 키-밸류를 묶어 놓는 데이터 형식이다.
hash {
field1 : "hello",
field2 : "world"
}

hset [hashname] [key] [value] // hash 만들기
hkeys [hashname] // hash의 키를 모두 출력
hget [hashname] [key] // hash의 특정 key의 값 출력
hgetall [hashname] // hash의 모든 키/값 출력
hdel [hashname] [key] // 삭제
hset myhash field1 "hello" // set. 해당 해쉬는 myhash라는 이름이며 key가 field1 value가 "hello"
// sudo json
myhash {
field1 : "hello"
}
hkeys myhash // myhash의 키를 모두 출력하라
hget myhash field1 // myhash의 field1 키의 값을 출력하라
hgetall myhash // myhash의 키/값을 모두 출력하라
hdel myhash field1 // 해당 field1을 지워라
2. 리스트 : rpush, lpush, rpop, lpop, lset
말 그대로 리스트입니다. 특정 인덱스에 값을 부여하면(lset) overwrite 됩니다.
Sets the list element at index to element.
LSET – Redis
Sets the list element at index to element. For more information on the index argument, see LINDEX. An error is returned for out of range indexes. *Return value Simple string reply *Examples redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two
redis.io
rpush [key] [value] // 말 그대로 list에 push
// LPUSH, LPOP, RPUSH, RPOP를 조합해서 스트를 큐(FIFO)와 스택(LIFO) 형태로 사용할 수 있음
lset [key] [index] [value] // 특정 index에 value 삽입 (An error is returned for out of range indexes.)
lrange [key] [start] [stop] // list를 start부터 stop까지 보여달라주의할점이, lset은 기존 리스트 index 내의 값이어야지, 새로운 value를 만들어내지는 못합니다.(redis.io/commands/lset)
결론적으로, 무언가 새로운 값을 넣으려면 rpush를 통해 넣어야 합니다.


3. 셋(set) : sadd, smembers
SADD – Redis
Add the specified members to the set stored at key. Specified members that are already a member of this set are ignored. If key does not exist, a new set is created before adding the specified members. An error is returned when the value stored at key is n
redis.io
python에서 set 자료 구조 사용해보셨죠? 집합을 표현하기 위한 자료구조이고, 중복을 허용하지 않습니다.
sadd key [member...] // set 멤버를 추가합니다.
smembers [key] // set의 멤버들을 모두 출력합니다sadd test_set 1 2 3 4 // 1 2 3 4 추가
smembers test_set // 출력
sadd test_set 5 6 // 5 6 추가
smembers test_set // 출력

4. sorted set : zset/zrange
Adds all the specified members with the specified scores to the sorted set stored at key.
특정 score를 매겨 정렬할 때 편합니다. ranking 관련 로직을 개발하는데 아주 유용합니다.
거의 실시간으로 바뀌어야 하는데 Disk를 사용하면 속도가 느리기 때문에 Redis sorted set을 많이 사용합니다.
* 랭킹 서버 만들기
DB에 유저 score 저장하고 order by 정렬을 한다. => 그러나 결국 디스크를 사용하므로 느려짐
따라서 in memory를 사용함. redis의 sorted set를 이용하면 편리하게 sorting도 가능함.
* score는 double 타입이다. 그래서 실수값으로 표현할 수 없는 정수값들이 존재하므로 정확하지 않은 score가 들어가는 이슈가 발생할 수 있다.
zadd [key] [score member ...]
zrange [key] [start] [end] [withscores] // withscores를 붙이면 점수까지 출력됩니다.
이 보다 더 많은 자료 구조에 대해서는
위에 첨부한 문서와 더해 아래 게시물을 참고해보도록합시다.
In memory dictionary Redis 소개
redis Introduction Intro Redis는 "REmote DIctionary System"의 약자로 메모리 기반의 Key/Value Store 이다. Cassandra나 HBase와 같이 NoSQL DBMS로 분류되기도 하고, memcached와 같은 In memory 솔루션으로..
bcho.tistory.com
www.zerocho.com/category/NodeJS/post/5a3238b714c5f9001b16c430
(NodeJS) Redis - Node와 연동하기
안녕하세요. 이번 시간에는 Redis를 배워보고 노드와 연동하는 방법에 대해 알아보겠습니다. Redis는 NoSQL 데이터베이스 중 하나로 다양한 자료구조를 저장할 수 있습니다. NoSQL 데이터베이스가 많
www.zerocho.com
'DB, ORM > 🟥 Redis' 카테고리의 다른 글
| Redis 운영 이슈와 효율적 이용을 위한 redis.conf 설정 (0) | 2020.12.30 |
|---|---|
| Redis를 활용한 Look aside 방식의 캐싱 in node.js (0) | 2020.12.29 |
| Redis Persistence (0) | 2020.12.29 |
| Redis : pub/sub model (0) | 2020.12.28 |
