인덱스(색인)
https://darrengwon.tistory.com/454?category=901178
1️⃣ 쿼리를 수할 때 인덱스가 없다면 모든 도큐먼트를 조회해야 한다. 효율적인 쿼리 작업을 위해 인덱스를 사용하자.
2️⃣ 인덱스를 만들면 새로운 도큐먼트를 만들거나 삭제할 때 속도 저하 문제가 일어날 수 있다. B-Tree 자료구조의 특성상 생성/삭제시 매번 인덱스를 다시 써야 하기 때문이다. (예를 들어, 3번 인덱스를 지우면 그 이후 도큐먼트의 인덱스를 -1 씩 해주는 작업을 해줘야 함. )
3️⃣ single 인덱스를 만들면 해당 필드만 조회할 때만 유용하다.
4️⃣ compound 인덱스는 순서가 중요하다.
5️⃣ a-b 복합 인덱스는 a 단순 인덱스와 같은 기능을 한다. 그러나 b 단순 인덱스로는 인덱스를 온전히 활용할 수 없다. a인덱스로 정렬이 이미 한 번 이뤄진 상태이기 때문이다.
B-Tree
mongoDB에서 인덱스는 어떤 필드에 대한 값을 검색하기 쉽도록 해당 필드의 값들을 B-Tree 구조로 만들어서 저장한다. B-Tree 자료구조란 하나의 노드가 가질 수 있는 키의 최대 갯수가 2보다 큰 트리 구조를 말한다.
첨부한 이미지를 보면 무엇을 말하는지 알 수 있을 것이다. Binary Tree는 노드가 하나의 키를 가지고 있지만 B-Tree는 하나의 노드에 키들을 가질 수 있다. 아래 이미지에서 어떤 노드는 6, 8 이라는 두 개의 키를 가지고 있고, 9, 10, 11이라는 세개의 키를 가진 것도 볼 수 있다.
B-Tree에는 몇 가지 규칙이 있는데
1️⃣ 각 노드에 있는 키들은 전부 정렬 되어 있어야 한다. 노드 내부의 키가 6, 8 이어야지 8, 6이면 안된다는 것이다.
2️⃣ 이렇게 정렬된 키 사이 사이에 자식 노드들이 연결되어 있는데, 해당 키 사이에 연결된 자식 노드를 키 사이의 값만 가져야 한다.
말이 어려운데, 노드 (6, 8) 에서
6 왼쪽에 연결된 노드는 6보다 작아야 하므로 5가 올 수 있다.
6, 8 사이에 연결된 노드는 6보다 크고 8보다 작은 키를 가져야 하므로 7이 왔다.
8 오른쪽에 연결된 노드는 8보다 커야 하므로, 9, 10, 11 등이 올 수 있다.
이러한 특성 때문 mongoDB가 특정 값을 찾을 수 있게 된다.
에를 들어 아래 B-Tree에서 7을 찾아야 한다고 가정하자.
1. 그렇다면 루트 노드(4)가 7보다 작으므로 7은 4의 오른쪽에 연결되어 있을터이고
2. 오른쪽 노드의 6, 8을 보니 7은 그 사이에 연결된 노드일 것이다.
3. 그 사이 노드의 키값을 살펴보니 7이다. 찾았다.

그런데 B-Tree 뿐만 아니라 트리 구조는 자식 노드가 많아지게 되거나 하나의 노드에 키값이 적게 들어 있다면 검색 효율이 떨어 지게 된다. 또, 새로운 정보를 추가하거나, 삭제하게 되면 새롭게 노드를 쪼개거나 합치는 등의 '균형 맞춤' 과정을 다시 해야 하기 때문에 생성/삭제 작업이 자주 이뤄지는 필드라면 인덱스를 함부로 생성하지 않는 것이 좋다.
single 인덱스 (단일키 인덱스)
https://docs.mongodb.com/manual/core/index-single/
한 가지 종류의 키값을 가지는 방식을 '단일키 인덱스'라고 부른다.
{score: 1}이라는 인덱스를 넘기면 오름차순으로 score 필드를 정렬하게 된다.
이제 score에서 45이상, 60이하인 도큐먼트를 찾을 때 빠르게 찾을 수 있게 된다. 이미 정렬을 해둔 상태이기 때문이다.
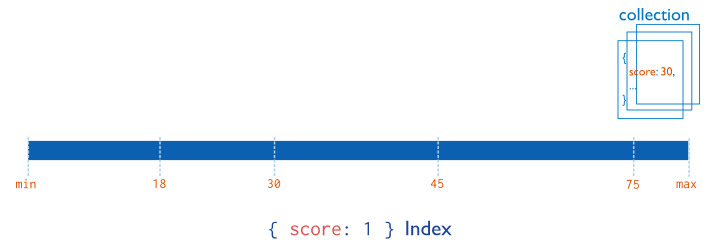
단순 인덱스의 단점은, 두 가지 필드를 한 번에 검색할 때 효율적이지 못하다는 것이다.
예를 들어 45이상, 60 이하의 점수에 이름이 '김'으로 시작하는 도큐먼트를 검색한다고 가정해보자.
45이상, 60이하 점수에 해당하는 도큐먼트는 빠르게 찾은 후, '김'으로 시작하는 도큐먼트를 일일히 찾아야 한다.
(그래도 아무 인덱스가 없는 것보다는 빠르다)
compound 인덱스(복합키 인덱스)
https://docs.mongodb.com/manual/core/index-compound/
여러가지 필드 검색을 효율적으로 하기 위해서는 복합키 인덱스가 필요하다.
{userid: 1, score: -1} 인덱스를 생성하면, userid로 오름차순 정렬한 다음, score로 내림차순 정렬한다.
userid가 b로 시작하는 도큐먼트 중 score가 30점 이상 60점 이하인 도큐먼트를 빠르게 검색할 수 있다.
또, userid가 b로 시작하는 도큐먼트를 가져오라는 단일 인덱스의 기능을 할 수 있다. 이미 userid로 정렬이 되어 있기 때문이다.
반면 score가 30점 이상 60점 이하인 도큐먼트만 가져오는 것은 인덱스의 효과를 누릴 수 없다.
compound 인덱스에서 한 가지 중요한 건, '범위'와 '값'을 구분하는 것이다.
위의 예에서 {userid: 1, score: -1} 로 인덱스가 설정되어 있는데 만약 userid가 b로 시작하고(범위) score가 정확히 60점(값)인 도큐먼트를 찾는 것은 인덱스의 효과를 누릴 수 있게 된다. userid의 범위를 찾고 해당 도큐먼트 안에서 score가 60인 값을 찾으면 되기때문이다.
이래서 compund 인덱스에서는 '순서가 중요'하다는 것이다.
따라서, 일반적으로, 포괄적인 필드에 우선적으로 인덱스를 적용하는 것이 좋다.

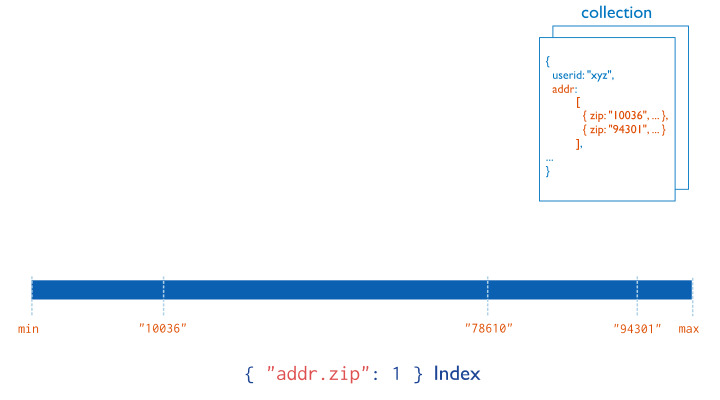
multikey 인덱스
https://docs.mongodb.com/manual/core/index-multikey/
쉽게 말해 도큐먼트의 필드값이 배열인 경우에 인덱스를 설정하는 겁니다.
text 인덱스
https://docs.mongodb.com/manual/core/index-text/
문자열 검색에 최적화된 인덱스입니다.
예를 들어 "해외 최신 영화"를 검색한다고 가정한다면, 유저는 "영화"라는 단어만 입력하지 문자열 전체를 '정확'하게 입력하는 경우는 별로 없습니다. 이러한 검색 기능을 도와주는 인덱스로 text 인덱스가 있습니다.
텍스트 인덱스는 하나의 컬렉션에 단 하나만 만들 수 있습니다.
hash 인덱스
https://docs.mongodb.com/manual/core/index-hashed/
값을 직접 인덱싱하지 않고 값을 해시화 하여 작은 크기로 변형된 값을 B-Tree 구조로 인덱싱하는 것
본래의 값을 변형하기 때문에 범위검색과 정렬을 할 수 없고, 정확한 값을 검색할 때만 해시 인덱스를 사용할 수 있따.
또, 해시 인덱스 필드를 포함한 compound 인덱스를 생성할 수 없으며 배열을 값으로 가지는 필드에는 생성할 수 없다.
이러한 점 때문에 hash 인덱스는 일반적인 상황에서는 사용하기 힘들다.
'DB, ORM > 🍃 mongoDB (shell)' 카테고리의 다른 글
| 인덱스 (3) 쿼리 속도 측정을 위한 explain (0) | 2020.07.25 |
|---|---|
| 인덱스 (2) 인덱스 명령어 (0) | 2020.07.25 |
| 집계 명령어 활용하기 (3) Aggregate 파이프라인 (ii) 👨🏫 고급(?) stage (0) | 2020.07.25 |
| 집계 명령어 활용하기 (3) Aggregate 파이프라인 (i) 👨🏫 기본적인 stage (0) | 2020.07.24 |
| 집계 명령어 활용하기 (1) 몽고 DB의 아키텍쳐와 집계의 효율성 (0) | 2020.07.24 |
